cuda编程的基础概念总结
GPU的基础介绍
首先上一张显卡主板构造图。

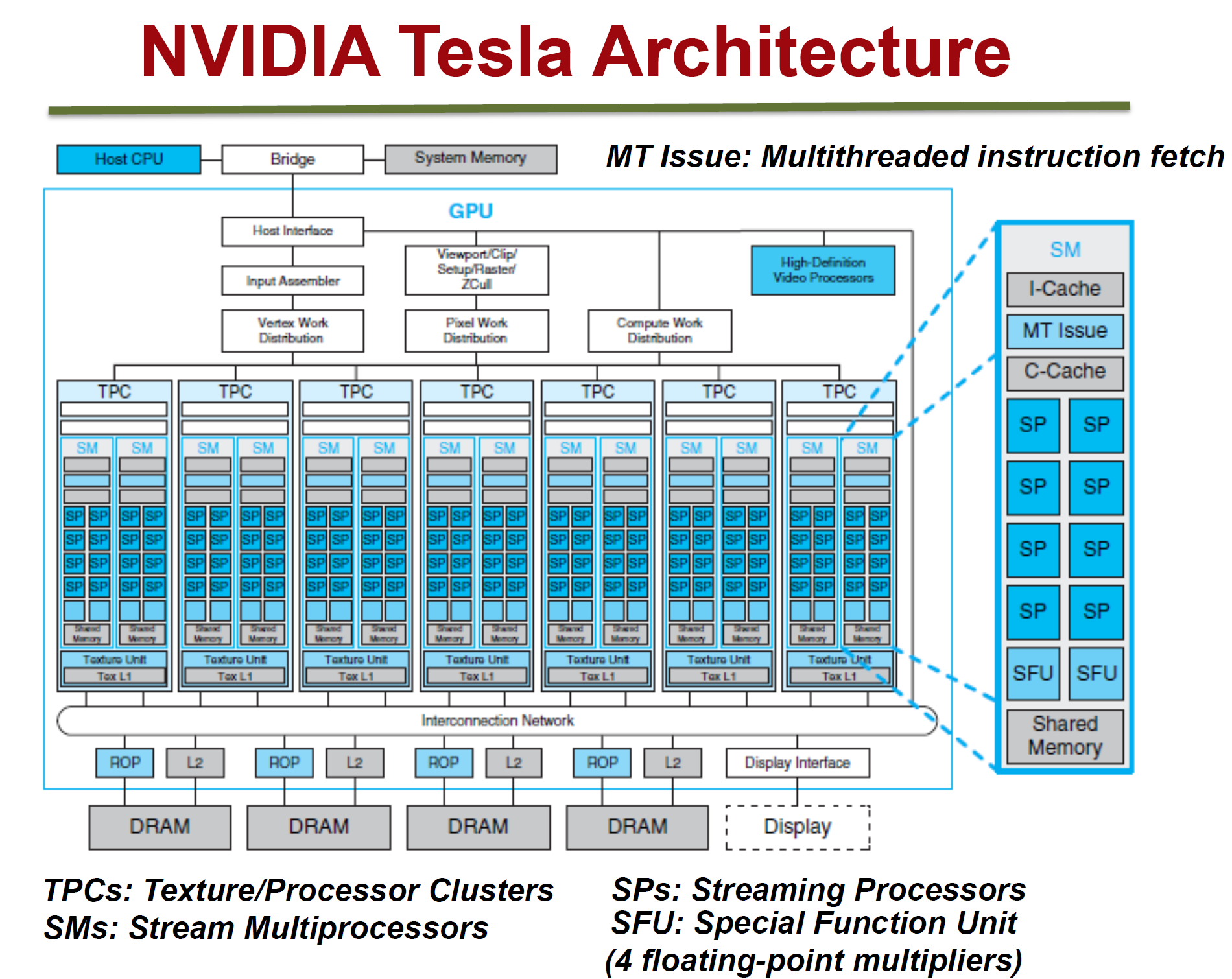
其中GPU芯片是重点,其结构图如下,它一般有很多核心,这些核的学术名字叫流多处理器(stream multiprocessor,SM),每个SM根据GPU型号的不同由若干个流处理器(stream processor,SP)组成,SP的功能只有计算。
cuda编程的基本概念
主机端host与设备端device
一个工程,我们想要有的代码在cpu上执行,有的代码在gpu上执行。因此就需要有host与device的概念。
GPU是完全不同于CPU的处理器,为了方便地同时为CPU和GPU编写代码,处理好两种处理器间各自计算、内存、数据传递等任务,CUDA使用C语言作为CPU端的开发环境,并在GPU端使用几乎与CPU端一致的语法进行开发,只是使用一些特定的关键字来区分CPU端和GPU端的代码。
CUDA中,为了更好的区分CPU和GPU,将CPU作为主机端(Host),GPU作为设备端(Device),每个进程(process)中,通过一个Host控制一个或多个Device协同工作。通过这种方式,CPU负责进行逻辑性强的事务性处理和串行计算,而GPU则专注于执行高度线程化的并行处理任务。
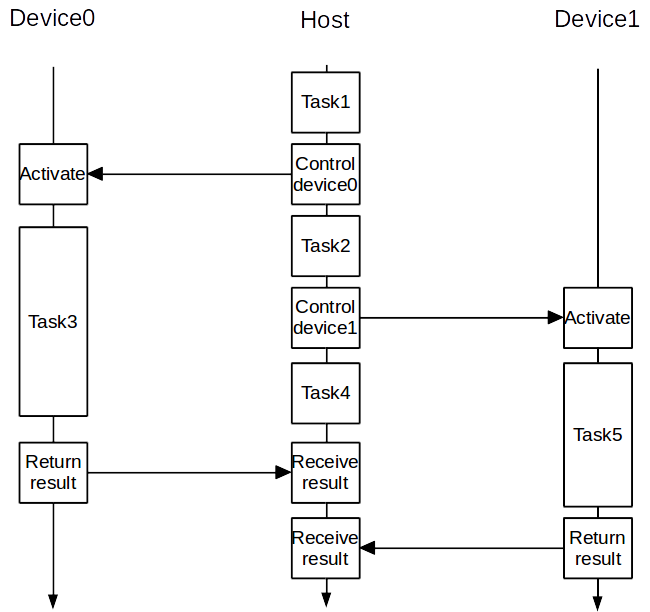
通过这种方式,首先实现了CUDA中最上层的并行:Host与Device的并行。也可以理解为将计算任务分解成若干子任务分别交给CPU和GPU。如下图所示,Host和Device有各自的流水线,计算和内存等均彼此独立,不过Device依然由Host控制,控制Device的工作也是Host流水线上的一部分。
虽然在大多数时候,为了结果的正确性需要经常在必要处进行Host与Device同步(往往是CPU、GPU间的数据通信),此时CPU或GPU会空等另一边执行到同步出再继续计算。但在此基础上进行进一步优化往往可以带来很好的优化效果,比如采用通信隐藏、或者插入无关计算等方法。
在正常c语言中,设备端函数用
__global__来修饰。在执行时需要使用特定的调用格式。
设备端代码的执行
一般从主机代码中启动设备代码叫做内核调用。内核调用有固定的语法
func << <block数量,每个block中线程数量,共享内存大小 >> >(参数列表)
CUDA中,运行在GPU上的并行计算函数称为kernel函数。
内核调用是以线程网格(grid)的形式组织的,每个grid由若干个线程块(block)组成,而每个block又由若干个线程(thread)组成。block的数量只要小于\(2^{31}-1\)就好,thread的数量现在一般都是1024了。
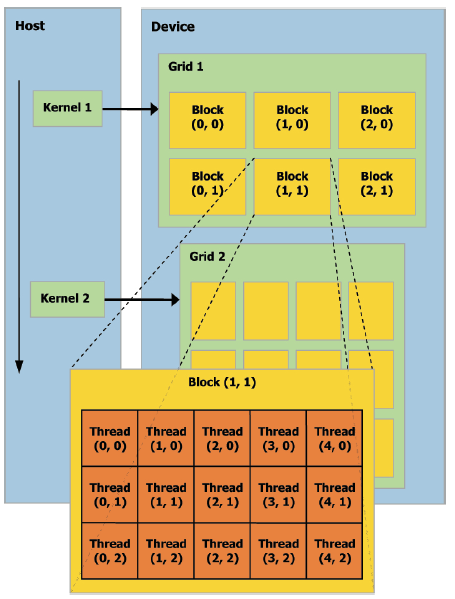
一般block数量是GPU的流多处理器数量的两倍时,GPU会给出最佳性能。
cuda编程时的内存结构
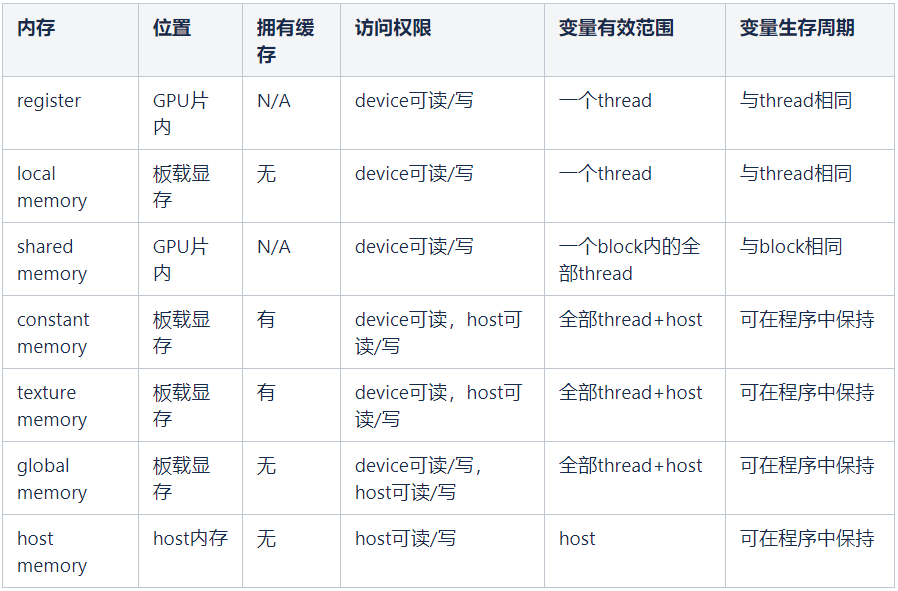
除了表格中的,其实还有L1和L2缓存。其中L1缓存一般是每个流多处理器(gpu的核)都有的,一般与shared memory使用相同的存储硬件,L2缓存是整个gpu中所有的流多处理器共享的,所有的global memory和local memory都使用这些缓存。同时,所有的global memory访问通过L2缓存进行。
在__global__修饰的设备函数中声明的局部变量肯定使用的是local
memory或者是register(一开始会优先使用register,如果register装不下,就会使用local
memory);而使用cudaMalloc分配的内存都是global memory
此处说的global memory对应的物理结构也就是本文开头的显卡主板构造中的显存芯片,这是在gpu芯片之外的,因此访问速度会比较慢。
上面的shared memory是在gpu芯片内部,因此速度比global
memory快很多。一般在设备函数中使用__shared__修饰声明的变量存储在shared
memory中,供同一个block中的所有线程使用。
上面的constant
memory也是占用的显存,并且逻辑上分配64kb大小的常量内存空间,这部分内存是只读的。其中的变量一般在全局程序中使用__constant__关键字修饰,对常量内存中的变量进行初始化需要使用cudaMemcpyToSymbol函数。在设备函数中常量内存是只读的,因此每个线程在访问常量内存时不是单独访问,而是统一一次访问,然后广播给所有的线程,因此在频繁访问同一块常量内存时可以节省时间。
上面的texture memory是另外一种当数据访问具有特定模式的时候可以加速程序执行、减少显存带宽的只读存储器。纹理内存也是在显存芯片中,和常量内存一样都在芯片内部被cache缓冲。当每个线程的读取位置都与其他线程的读取位置临近时,使用纹理内存会很高效。
CUDA对于显存中常见的大数据量的存储方式有两种,一种是普通的线性存储(cudaMalloc申请),可以直接用指针访问。另一种则是cuda数组(一般与纹理内存绑定),对用户不透明,不能在内核里直接用指针访问,需要通过texture或surface的相应函数访问。
主机内存
一般cuda编程都会涉及到主机与设备之间的内存交换,而主机内存需要注意的是:
- 使用
malloc函数在cpu上分配的内存是可换页的标准内存; - CUDA提供了
cudaHostAlloc函数可以分配锁定页面的内存,也叫Pinned内存;操作系统会保证永远不会将这种内存换页到磁盘上,总在物理内存中,因此系统内的所有设备都可以直接用该段内存缓冲区的物理地址来访问,此属性可以帮助GPU通过直接内存访问(DMA)将数据复制到主机或从主机复制数据,无需cpu干预(cuda流中的传输需要使用页面锁定内存);
CUDA流
GPU作为一种专用的并行计算设备,可以同时支持多个内核调用,为了使得这个内核调用互不干扰,独立运行,可以使用CUDA流来组织不同的任务。每个流中的工作是串行的(比如从cpu拷贝内存,内核调用,拷贝内存回cpu,依次执行),而流与流之间则是默认不保证顺序的(并行互不干扰的)。
.cu程序编译
带有cuda编程的源文件一般是.cu结尾的,这种源文件的编译使用nvcc编译器,使用方法与gcc一致。