哈希表的原理与实现
哈希表(hash table,也叫散列表),是可以根据键(key)直接访问值(value)在内存中存储位置的一种数据结构。哈希表的核心是哈希函数(hash function),正是哈希函数完成了从key到value存储位置的映射。
在计算机科学中的应用
哈希算法在计算机科学中应用广泛。例如git的版本管理、IP协议中的checksum都有它的身影。 - 其中在git的版本管理中,文件内容是key,通过SHA算法(一种哈希函数)将文件内容对应为固定长度的字符串(hash值)。如果文件内容发生变化,那其所对应的字符串就会发生变化。git通过比较比较短hash值(字符串),就可以知道文件内容是否发生了变动。
- 还有一种应用是用于计算机的登录密码的存储。密码一般都是一串字符,但是为了安全问题,计算机不会直接保存这个字符串,而是保存该字符串的hash值(可以使用MD5、SHA或者其他算法作为hash函数)。当用户下次登录时,输入密码字符串。如果该密码字符串的hash值与保存的hash值一致,那么就认为用户输入了正确的密码。这样就算黑客闯入了数据中取出了密码记录,也只能看到密码的hash值。一般hash函数都会有很好的单向性,从hash值很难回推处键值。不过有一些网站存储的是明文密码。
需要注意的一点是,hash只要求完成从key到value的映射,并没有限定该对应关系必须是一一映射。因此会出现两个不同的key对应同一个value的情况。这种情况叫做哈希碰撞(hash collision)。比如通常MD5算法常用来计算密码的hash值,但是已有实验表明,MD5算法有可能会发生碰撞,也就是不同的明文密码生成相同的hash值,这给系统带来了很大的安全漏洞。
哈希表与搜索
哈希表被广泛应用于搜索。设定集合A为搜索对象,集合B为存储位置。可以通过hash函数将搜索对象与存储位置对应起来。这样我们只需要一次hash计算,就可以找到对象存储的位置。这就是C++中的unordered_map(map对应的是红黑树)与python中的dict的原理。
哈希表的实现
实现的话,一般很常见的是使用一个数组来存储对象,然后通过对键值进行hash计算来确定对象在数组中的存储的下标,由于数组可以根据数组下标进行随机存取(random access,算法复杂度为1),所以搜索操作将取决于hash函数的复杂程度。
下面是一个简单的例子,我们以人名(一个字符串)为key,以数组下标为对应的hash值。每一个数组元素中存储了一个指针,指针指向对应的关于这个人的记录(有人名和电话号码)。
如下是一个简单的hash函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#define HASHSIZE 1007
/* By Vamei
* hash function
*/
int hash(char *p)
{
int value=0;
while((*p) != '\0') {
value = value + (int) (*p); // convert char to int, and sum
p++;
}
return (value % HASHSIZE); // won's exceed HASHSIZE
}
1 | |
hash函数的计算是通过将key中的每个字母的ACII值相加然后求除以1007的余数,得到一个在0~1006之间的index值。我们建立一个1007大小的数组用于存储指向每个记录的指针。一般HASHSIZE被选择为质数,以便hash值可以分布的更加均匀。下图是hash搜索的一个示例,输入"Vamei"得到在数组index为498的地方存储着一个指针指向“Vamei”的记录。
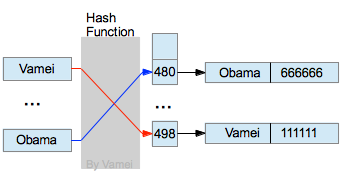
如果步采用hash,只在一个数组中进行搜索的话,我们需要一次访问每条记录,知道找到目标记录,算法复杂度为n。而利用键值使用hash函数进行查找,在没有hash碰撞的情况下,我们只需要一次hash计算就可以找到我们想要的元素。
hash碰撞的解决
由于不是一一映射,所以hash函数需要解决hash冲突的问题。比如上面的那种hash函数的映射方式,"Obama"与“Oaamb”有相同的hash值,发生冲突。
- 一种解决方案是将发生冲突的记录使用链表进行存储,让hash值处的数组元素指向该链表。这种方法叫做open hashing
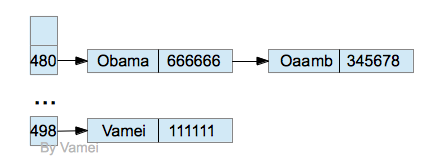
这种方法我们需要将每个记录的数据结构封装成链表节点,在通过hash值找到这个链表后,通过遍历链表找到想要的记录。
- 还有一种解决方案是当冲突出现时,我们将冲突记录放在数组中依然空闲的位置,比如图中的"Obama"被插入后,随后的“Oaamb”计算hash值也是480。但是由于480已经被占据,于是找到下一个空闲位置481进行记录。这种方法叫做closed hashing
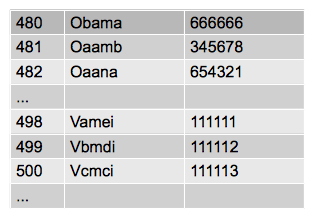
closed hashing的关键在于如何找到下一个位置。上面的做法是
index+1。但是也可以是其他的方法。当我们在搜索的时候,首先依据hash函数找到初始index,通过比对key值,如果不是想要的记录,就不断的找下一个位置,直到找到想要的记录。
如果HASHSIZE太小,会导致hash碰撞太多,此时会极大地影响查找效率。我们需要增大HASHSIZE,并将原来的记录放入新的比较大的数组中,这样的操作叫做rehashing。
c语言实现见我的github里c语言学习文件夹c_learn/hash_table
参考资料
- [1] https://zh.wikipedia.org/wiki/%E5%93%88%E5%B8%8C%E8%A1%A8
- [2] http://www.cnblogs.com/vamei/archive/2013/03/24/2970339.html