Inception概念解析
Inception 由来
2014年,GoogLeNet在ImageNet竞赛上击败VGGNet一举夺魁。其中,GooLeNet首次提出Iception结构,早期的Iception-v1结构借鉴了NIN(Network in Network)的设计思想,对网络的传统卷积层进行了修改,并一直改进到v4,改进过程中主要是针对以下限制神经网络性能的主要问题: 1. 参数空间大,容易过拟合,且训练数据集有限; 2. 网络结构复杂,计算资源不足,导致难以应用; 3. 深层次网络结构容易出现梯度弥散,模型性能下降。
Inception
首先,一开始提出Inception为的是增加网络的适应能力。应用到图像领域,层级越高,所对应的原始图像的视野就越大,同样大小的卷积核往往难以捕捉到不同的特征。因而层级越高,卷积核的数目也应该增加,即使用不同尺寸的卷积核共同进行特征提取。
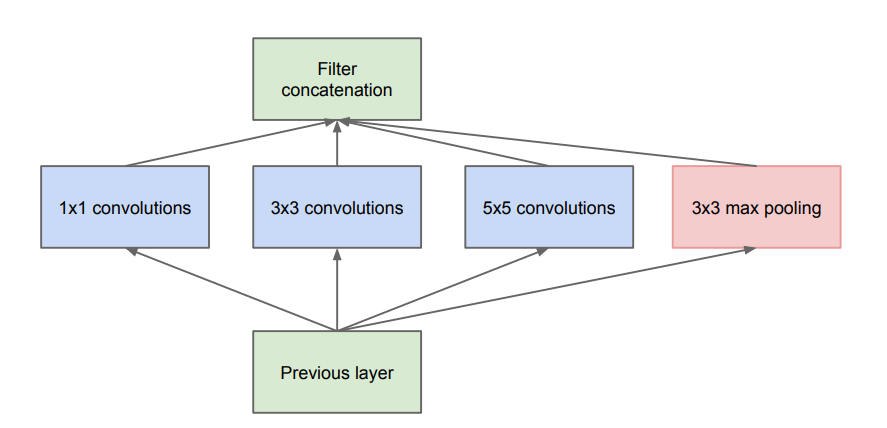
如上图所示,分别使用了1×1、3×3、5×5的卷积核,并且加入了3×3的max pooling。但是这样的结构存在着明显的问题:每一层的Inception结构上的参数量为所有分支上参数量的总和,多层Inception最终会导致模型的参数数量庞大,对计算资源需求巨大。
Inception_v1
为了减少计算量,在不损失模型特征表示能力的前提下,在v1中又提出了使用1×1卷积核进行降维,达到降低模型复杂度的目的:
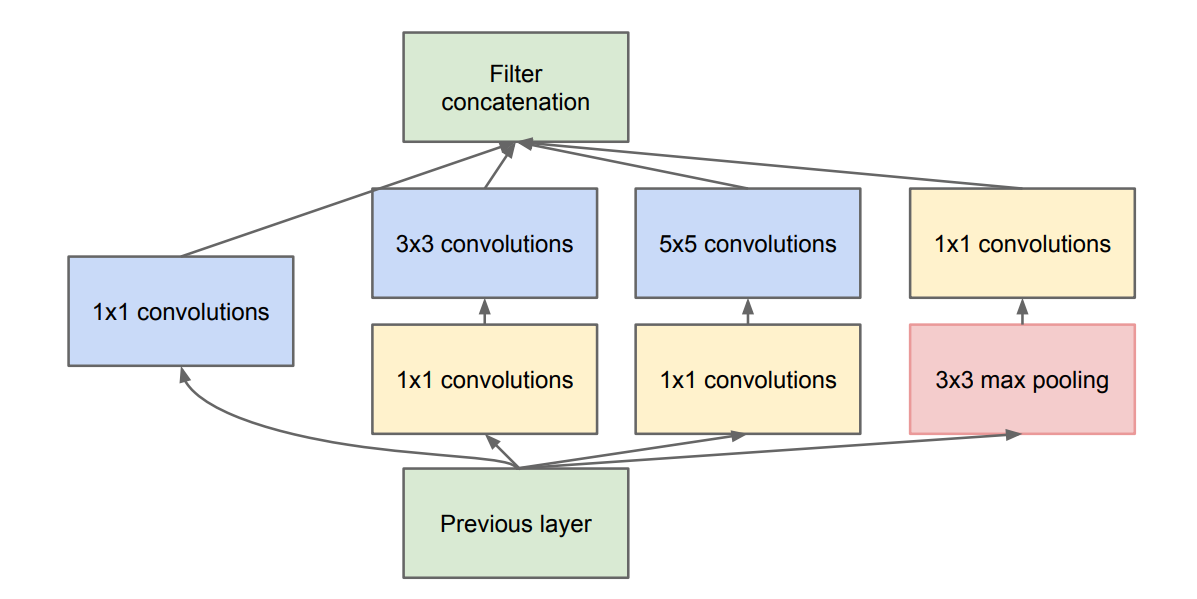
如图,在3×3、5×5的卷积核之前,使用1×1卷积核进行降维,大大减少了参数量。
- 1×1卷积核降维原理:比如100×100×3的图片,直接3×3卷积核卷积共进行
a=100×100×3×3×3此运算。而使用1×1卷积核首先进行b=100×100×3次运算,然后再与3×3卷积核卷积进行c=100×100×3×3次运算,明显a>b+c(计算运算量时只考虑了乘法数量)。
Inception_v2
Inception_v3
Inception_v4
Inception概念解析
http://line.com/2018/06/20/2018-06-20-Inception/